この記事は金沢工業大学 ロボティクス学科で2021年後学期開講中のロボットプログラミングⅡ用です.
今回も音声認識と同様にPythonライブラリをROS2化します。使用する音声合成ライブラリはgTTS(Google Text-to-Speech)です。これは、Google Translate text-to-speech APIのインタフェースとなっています。Googleのサービスを使うのでオンラインでのみ使用可能です。詳細は以下の公式サイトをご覧ください。
gTTSのサンプルコード
では、早速、gTTSを使ったサンプルを見てみましょう!
from gtts import gTTS
from subprocess import run, PIPE
tts = gTTS('I am Happy Mini', lang='en')
tts.save('text.mp3')
CMD = 'mpg321 text.mp3'
run(CMD.split(), stdout=PIPE, stderr=PIPE)
- インストール
$ sudo apt install sox$ sudo apt install mpg321$ pip install gTTS
- コードの作成
$ mkdir -p ~/src/gTTS$ cd ~/src/gTTS- ここで,gtts_example.pyというファイルをgtts_example.pyに作成しなければいけません. そのために好きなエディタnanoやgedit等で上のサンプルコードをコピペしてgtts_example.pyとして~/src/gTTSディレクトリの中に保存してください.なお,nanoの使い方がわからない方はこのリンクを見てください.
- 例
$ nano gtts_example.py
- 例
- 実行
$ cd ~/src/gTTS$ python3 gtts_example.py
“I am Happy Mini”とスピーカーから聞こえてきたら成功です。
なお,WSL2を使っている学生は音が聞こえないと思います.次のリンクの設定が必要になります.WSL2では基本的にデバイスを直接扱えないのでリアルロボットを動かすことはできません.そのため,授業では推奨していません.
ROS2化
import rclpy # ROS2
from rclpy.node import Node # ROS2
from std_msgs.msg import String # ROS2
from gtts import gTTS
from subprocess import run, PIPE
import os
class SpeechSynthesis(Node):
def __init__(self):
super().__init__('speech_synthesis') # ROS2
self.CMD = 'mpg321 text.mp3'
self.recog_sub = self.create_subscription(String, 'recog_text', self.sub_cb, 10) #ROS2
def sub_cb(self, msg): # ROS2 サブスクライバ用のコールバック関数
print("Subscribe text:'{}'".format(msg.data))
tts = gTTS(msg.data)
tts.save('text.mp3') # 音声データをファイルに保存
run(self.CMD.split(), stdout=PIPE, stderr=PIPE) # 発話
os.remove('text.mp3') # ファイルを削除
def main():
rclpy.init() # rclpyの初期化
speech_synthesis = SpeechSynthesis() # ノードの生成
rclpy.spin(speech_synthesis) # ノードの実行
speech_synthesis.destroy_node # ノードの破壊
rclpy.shutdown() # rclpyの終了処理
if __name__ == '__main__':
main()
- パッケージの作成
$ ~/colcon_ws/src$ ros2 pkg create --build-type ament_python --node-name speech_synthesis speech_synthesis
- ソースコードの作成
- ビルド
$ cd ~/colcon_ws$ colcon build --symlink-install
- 実行
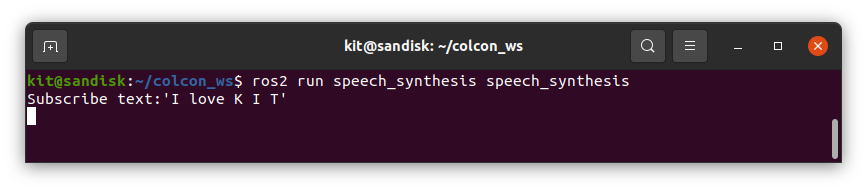
- 1つ目の端末で次のコマンドを実行
$ cd ~/colcon_ws$ source install/local_setup.bash$ ros2 run speech_synthesis speech_synthesis
- 2つ目の端末で次のコマンドを実行
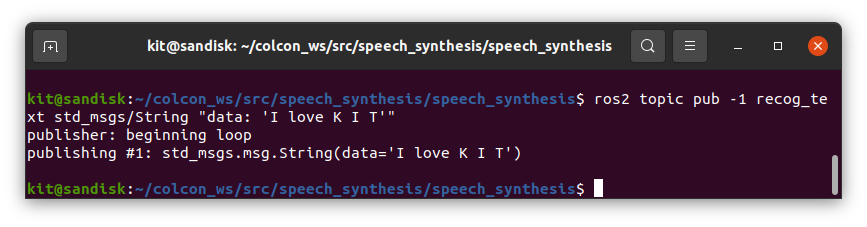
$ ros2 topic pub -1 recog_text std_msgs/String "data: 'I love K I T'"
- “I love K I T”と音が聞こえれば成功です!
- 1つ目の端末で次のコマンドを実行
ハンズオン
- 次の文章を発話させてみよう。
Stay Hungry. Stay Foolish. It was their farewell message as they signed off. Stay Hungry. Stay Foolish. And I have always wished that for myself. And now, as you graduate to begin anew, I wish that for you.
- rostopic pubコマンドを使って”I love K I T”と発話させましたが、これをpythonプログラムで実装しよう。
- オウム返しのpythonプログラムを作ろう。あなたの発話を音声認識エンジンで変換して、認識結果をトピック名/tts、メッセージ型std_msgs/Stringでパブリッシュします。次に、その認識結果をコンピュータに発話させるパッケージを作りましょう.
- 次のリンクはROS1の質問応答システムのサンプルプログラムです.これをROS2用にバージョンアップするプログラムを作り,動作を確認してください.
終わり。お疲れ様!

コメント