Wep Speech APIを使うと音声認識が簡単にできる。しかも、ROSパッケージは以下のサイトで公開されており、開発者furushchevさんの詳しい日本語の解説記事もある。本記事はその作業メモ。
- 解説記事:ROSを使ってWebインターフェース経由で音声認識する by @furushchevさん
- Github: https://github.com/tork-a/visualization_rwt by Tokyo Opensource Robotics Kyokai Association
- Web Speech API参考リンク
作業環境
- Ubuntu18.04
- ROS Melodic
- Google Chrome バージョン: 80.0.3987.87(Official Build) (64 ビット)(他のブラウザは対応してないようだ)
インストール
- 以下のサイトのとおり実施した。推奨されているaptでのインストールはmelodic用のパッケージが見つけられなかったのでソースからビルドした。wstoolはワークスペースのバージョン管理システム。https://github.com/tork-a/visualization_rwt
- ワークスペースを初期化する。
$ cd ~/catkin$ wstool init src
- ワークスペースに新しいリポジトリを設定する。
$ cd src$ wstool set visualization_rwt --git https://github.com/tork-a/visualization_rwt/
- ワークスペースのリポジトリをアップデートする。
$ wstool update
- 依存関係の解消
$ cd ~/catkin_ws$ rosdep install --from-paths src --ignore-src --rosdistro ${ROS_DISTRO} -r -y
- ビルド
$ catkin build
実行
- 端末を開き、以下のコマンドを実行する
- $ roslaunch rwt_speech_recognition rwt_speech_recognition.launch
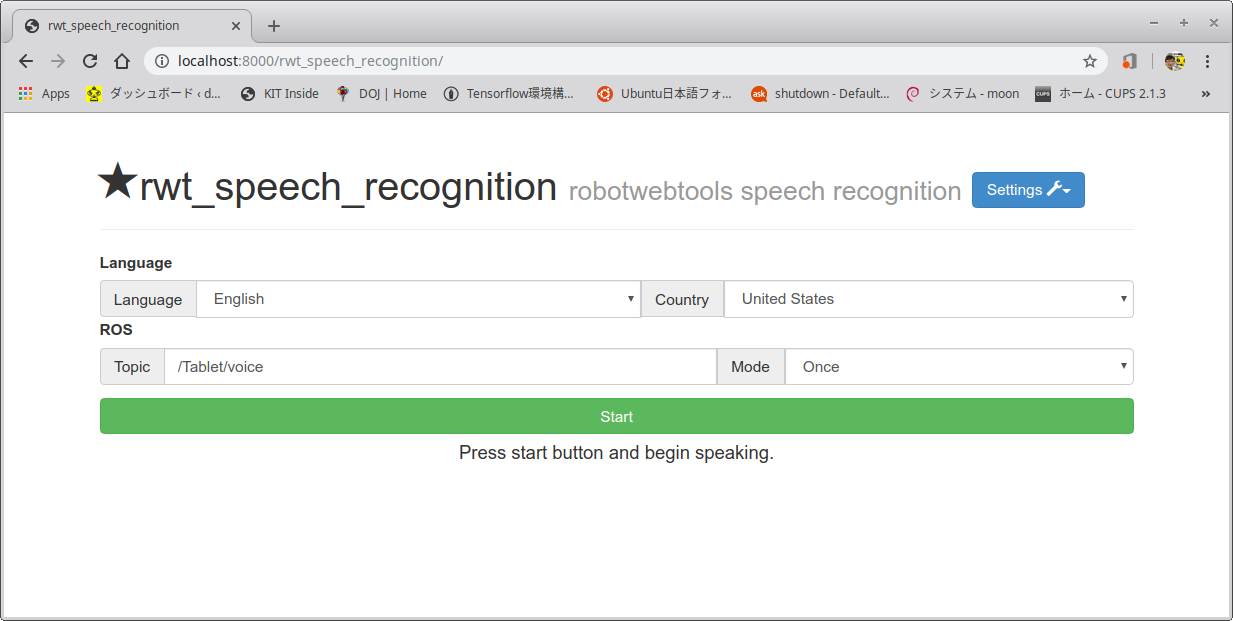
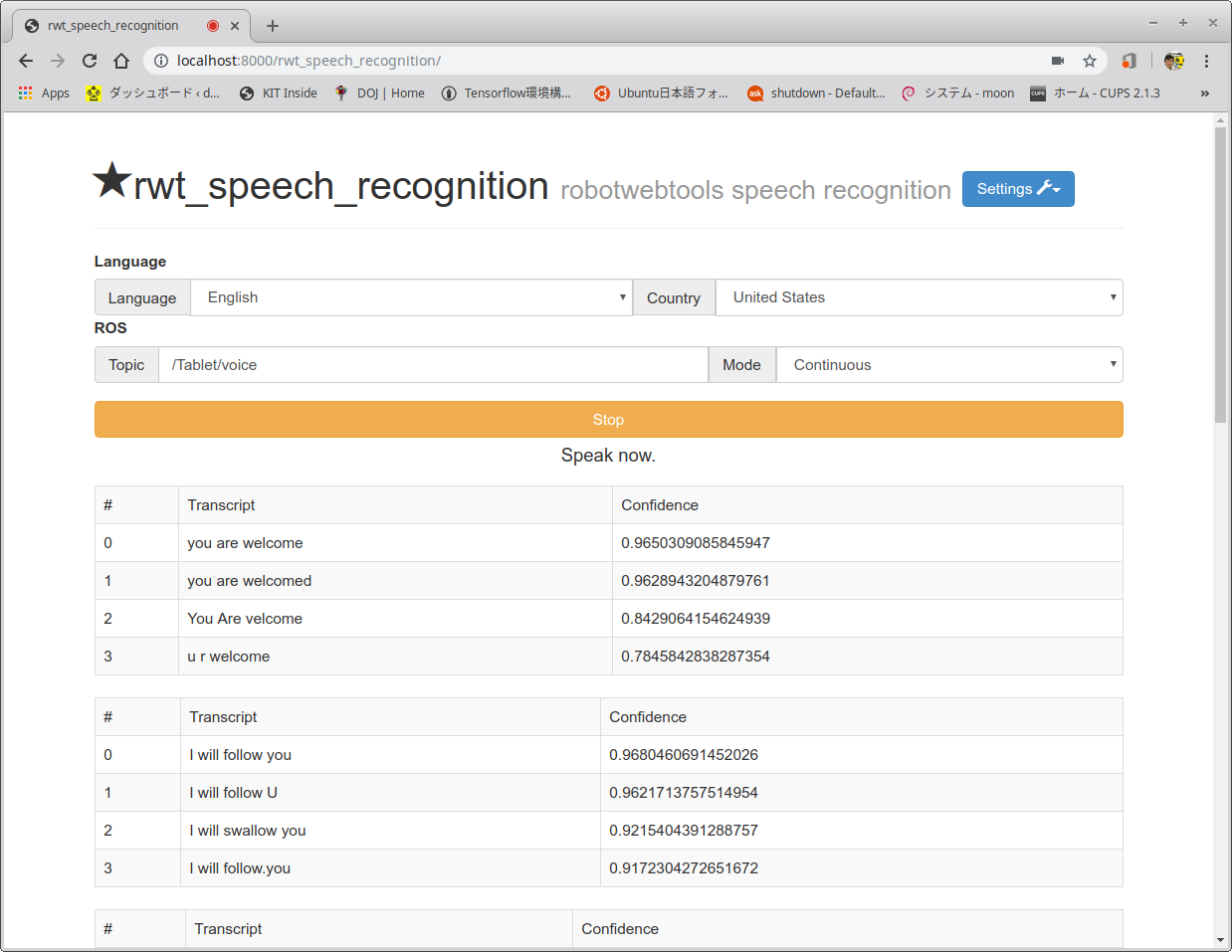
- 以下のリンクをクリックするかChromeブラウザを起動し以下のアドレスを検索窓に入れる。
- 音声認識をスタートさせるためには、以下のChrome画面で緑に塗られているStartボタンをクリックする。
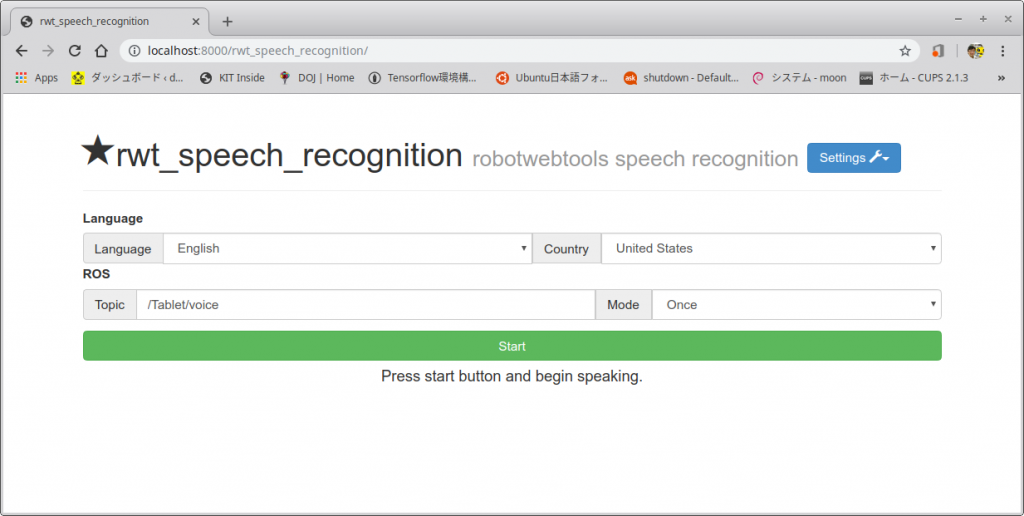
- Chromeの画面のマイクに英語で話しかけ、認識結果が表示されていれば成功。日本語で話しかけたい場合はブラウザのLanguageを日本語にすればよい。デフォルトではROSのトピック名が/Tablet/voiceになっているが、この画面から自由に変更できる。なお、連続して音声認識をしたい場合はModeをContinuousにすればよい。
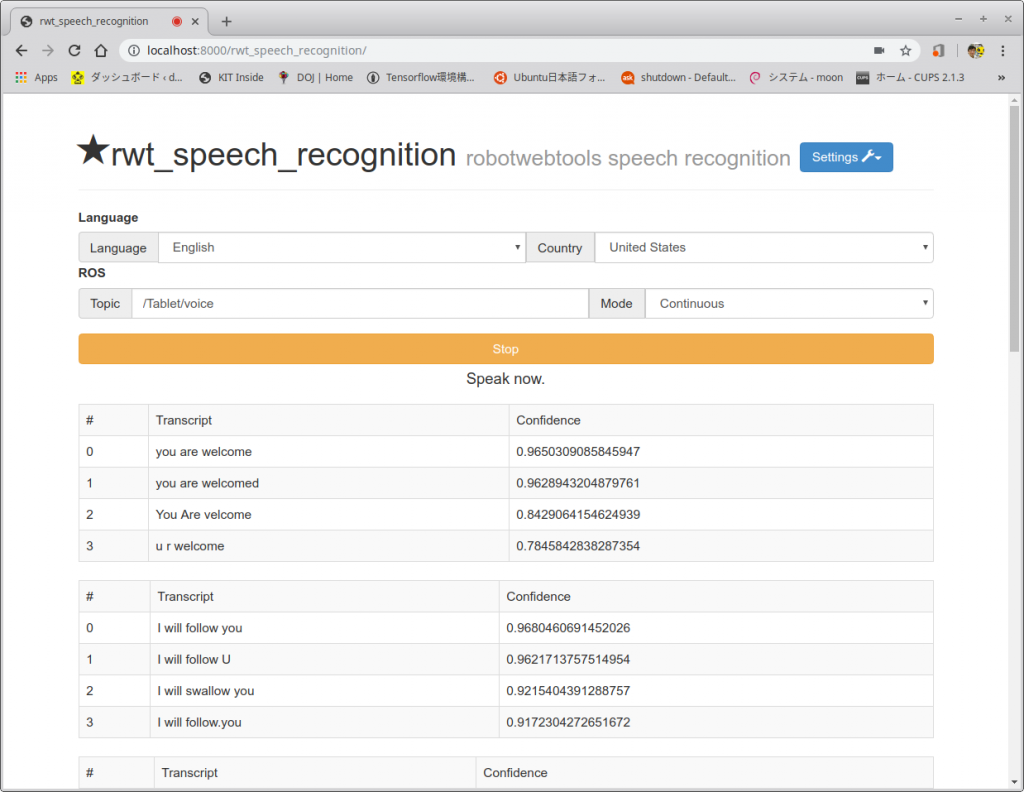
- では、最後にトピックを確認しよう。別の端末を開き、以下のコマンドで認識結果のトピック/Tablet/voiceを表示する。
$ rostopic echo /Tablet/voice
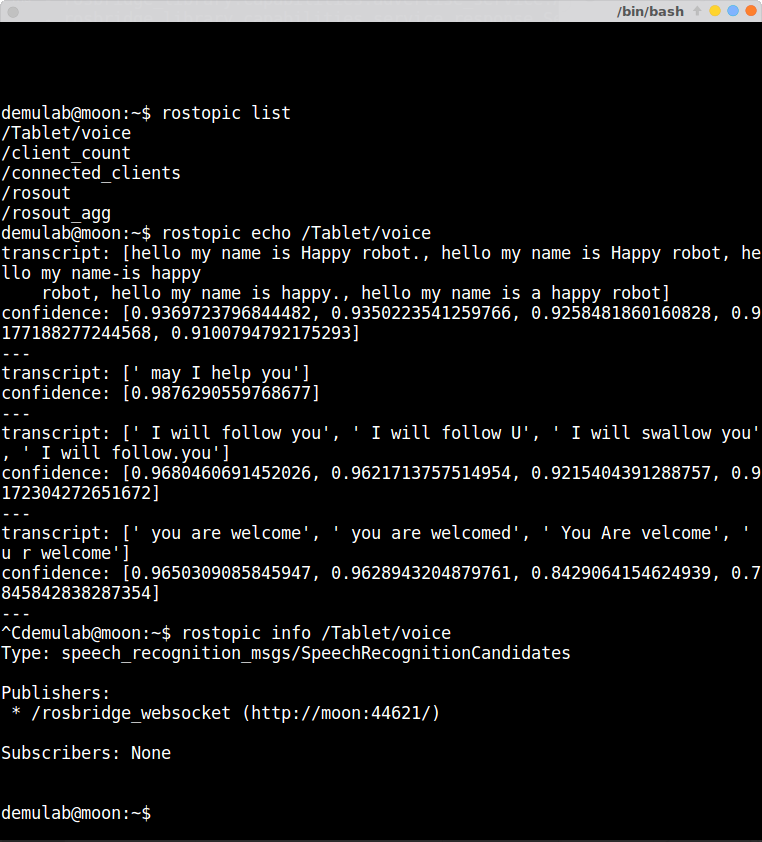
- うまくいかない場合は、インストールの4,5,6番の作業を繰り返してみよう。私の環境ではそれで問題が解決した。
カスタマイズ
- デフォルトではトピック名が/Tablet/voiceになっている。変更したいときは以下のファイル29行目のvalueの値を変更する。
- ~/catkin_ws/src/visualization_rwt/rwt_speech_recognition/www/index.html
以上
コメント