インスタンスセグメンテーション用アノテーションツールとして使っているVGG Image Annotator (VIA)の使用法のメモ。VIAはウェブベースのツールでHTML、Javascript、CSS以外のライブラリを使っていないのでWindows、Linux、Macでも簡単に利用できる。バージョン2.0.8ではCOCOフォーマットのアノテーションファイルをエクスポートできなかったが、2.0.10ではできるようになったのでありがたい。
ソフトウェアのインストールと準備
- 以下のURLから、via-2.0.10.zipをダウンロードし、好きなディレクトリに解凍する。この例では~/srcに解凍する。
- 画像を読み込むディレクトリと、プロジェクトを保存するディレクトリを事前に用意し、画像読み込み用のディレクトリに、アノテーションする画像を入れておく。この例では「sample」という名前で作成しているが、名前は自由。
- 端末を開き以下のコマンドを実行して、画像読み込み用のディレクトリを作成する。
- $ cd ~/src/via-2.0.10/data
- $ mkdir sample
- $ cd sample
- 訓練用データ、検証用データを格納する。trainとvalディレクトリを作成する。画像データをtrainに9割、valに1割になるように保存する。
- $mkdir train val
- プロジェクト保存用ディレクトリを作成する。
- $ cd ~/via-2.0.10
- $ mkdir project
- $ cd project
- $ mkdir sample
- $ mkdir train val
- 端末を開き以下のコマンドを実行して、画像読み込み用のディレクトリを作成する。
アノテーション作業
- ファイルマネージャーを使って以下のファイルをダブルクリックして起動する。
- ~/src/via-2.0.10/dist/via.html
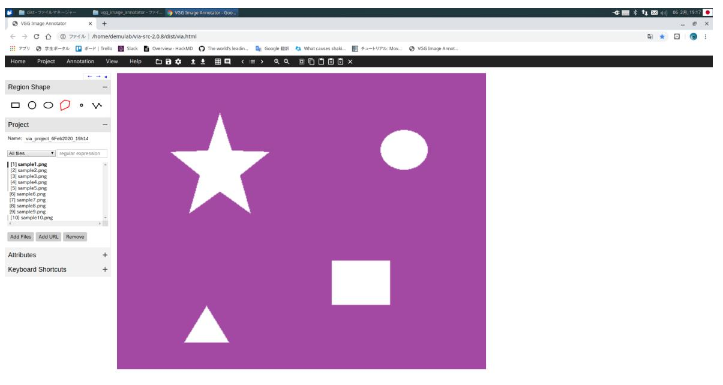
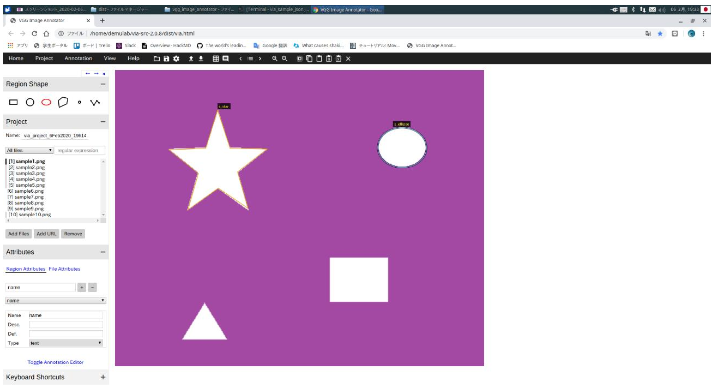
- 画像を読み込むには、左にあるバーの[Add Files]を左クリックした後に、画像読み込み用ディレクトリまで移動し、画像を選択する。選択に成功した場合、以下のような画面になる。
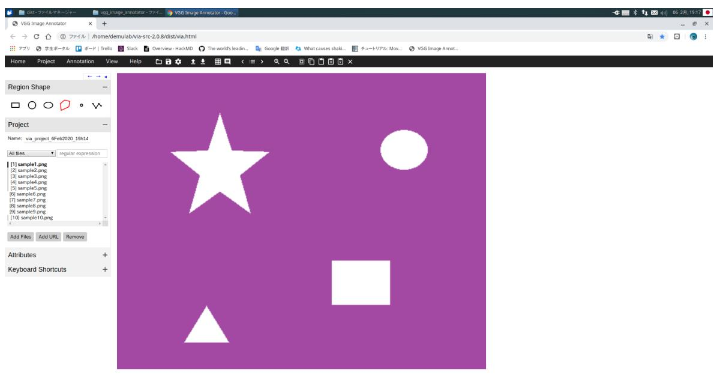
- Region Shapeの中の形状し、アノテーションする。右から3番目のPolygon region shape(多角形)を選択した場合は、多角形の頂点で左マウスボタンをクリックし、アノテーション終了時にはEnterキーを押す。
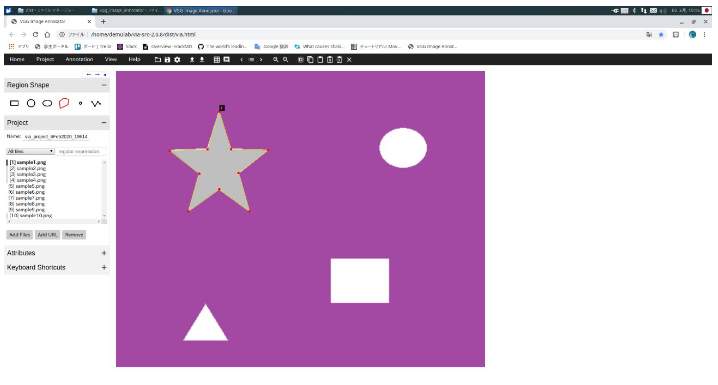
- アノテーションした各形状に固有の名前を付ける場合、左にあるバーのAttributesにキーボード入力できる欄がある。そこに「name」と入力し、横にある「+」を左クリックする。
- アノテーションした形状(ここでは星型)を左クリックすると、下図のようにクラス名を入力できるようになるため、そこに好きなクラス名を入力する。
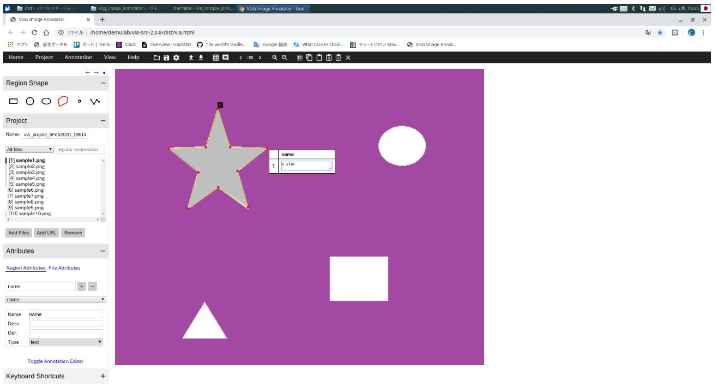
- AttributesのToggle Annotation Editorを左クリックすると、現在表示している画像におけるラベリング情報を見ることができる。また、そこでも固有の名前を入力できる。
- 現在、表示している画像のアノテーションが終われば、キーボードの「→」キーを入力し、次の画像をアノテーションする。このソフトウェアにおけるショートカットキーは、左のバーのなかにあるKeyboard Shortcutsの中に記載されている。他の例として、キーボードの「↑」「↓」キーを入力することで、以下の図のように、ラベリング情報の表示形式を変更できる。
JSONファイルの出力
アノテーションした情報を教師データとして使われるJSON(JavaScript Object Notation)フォーマットのファイルに出力する。JSONはウェブ等で良く使われる軽量のデータ交換フォーマットである。
- アノテーション作業が全て終了したら、その情報をJSONファイルに出力する。COCOフォーマットで出力したいときは、上のバーのAnnotationからExport Annotations (COCO Format)を左クリックして選択する。
- 「via-***_coco.json」というファイル名で保存される。このファイルは学習と検証に使われるので画像読み込み用ディレクトリのtrainまたはvalに移動させる。この例では、trainの中の画像をアノテーションしていると仮定しているので、端末を開き以下のコマンドを実行して、trainへ移動する。
- $ cd ~/src/via-2.0.10
- $ mv via_***_coco.json ~/via-2.0.10/data/sample/train
分担作業した場合のJSONファイルの作り方
アノテーション作業を複数人で実施して、お互いのアノテーションデータを統合したい場合が良くあると思うのでここで説明する。
- まず,複数人がアノテーション作業する全ての画像ファイルが重複しないようにファイル名を変換する.
- 各オブジェクトに対応するクラス名をあらかじめ決めておき,アノテーション作業ではそのクラス名を各オブジェクトに割り当てる.
- 各人のtrainディレクトリにある画像データをアノテーション作業した要領で読み込み、アノテーションファイルをメニューバーの[Annotation]→[Import Annotations (***)]から読みこむ。ここで***は保存したAnnotationの形式で、(from csv)、 (from json)、 (from COCO format)の3タイプがあるのでファイル名を見て適切なものを選択する。COCO formatの場合は拡張子jsonの前にcocoがついている(つまり、coco.json)。
- 画像ファイルの統合。統合用のtrainディレクトリを新たに作成する。各人のtrainディレクトリの画像ファイルを新しく作成した統合用trainディレクトリにコピーする。
- あとはアノテーションファイルを統合用trainディレクトリにエクスポートするだけ。[Annotation]→[Export Annotations (COCO format)]でファイルを統合用trainディレクトリにエクスポートする。
- 上と同じ作業をevalディレクトリに対しても行う。
プロジェクトの保存
アノテーション情報をプロジェクトとして保存することで、そのファイルを読み込めば前回終了した画像の続きからアノテーションを再開できる。
- プロジェクトの保存の前に、読み込んでいる画像へのパスを指定する。上のバーのProjectからSettingsに移動。
- Default Pathに画像へのパスを入力する。この例で、trainのディレクトリから読み込んでいるので、パスは以下になる。
- ~/src/via-2.0.10/data/sample/train/
- 最後に、下の「Save」ボタンを左クリックして設定完了。
- 次に、プロジェクトを保存する。上のバーのProjectからSaveを選択。以下の画面になるのでProject Nameを好きな名前に変更してOKを左クリックすると本プロジェクトがJSONファイル形式で保存される。この例ではstar.json
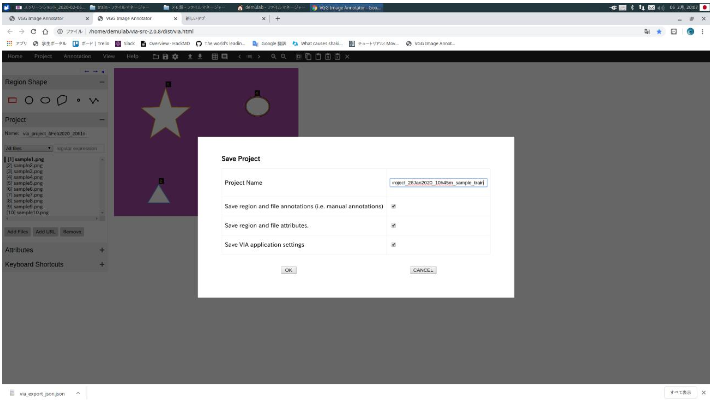
- このファイルをプロジェクト保存用ディレクトリに移動する。
- $ cd download
- $ mv star.json ~/via-2.0.10/project/sample/train
プロジェクトの読み込み
- 上のバーのProjectからLoadを選択する。そこからプロジェクト(JSONファイル(jsonファイル)
以上
コメント