この記事はHARD2021(Home AI Robot Development)スプリングワークショップ用です。 SpeechRecognitionというPythonの音声認識ライブラリはご存知でしょうか。CMU Sphinx、Google Speech Recognition、Google Cloud Speech API、Wit.aiなどのエンジンを使え、エンジンによっては日本語も扱えます。詳細は次のリンクをご覧ください。
今回は、このライブラリを使ったROSパッケージを作ります。望む機能を実現するROSパッケージがなくても、それを実現するために便利なライブラリさえあれば自分でROSパッケージを作ればよいわけです。
方法は今まで学んできたROSパッケージの作り方と同じで、出力用のパブリッシャと入力用のサブスクライバを作るだけです。
作業環境
- Ubuntu18.04
- ROS Melodic
SpeechRecognitionのインストール
- 端末を開いて依存関係のあるものをインストールする。
- $ sudo apt install linuxbrew-wrapper
- $ sudo apt install portaudio19-dev
- $ brew install portaudio
- $ pip install PyAudio
- ROSはPython2なので、SpeechRecognitionのPython2版をインストールする。
- $ pip install SpeechRecognition
SpeechRecognitionのテスト
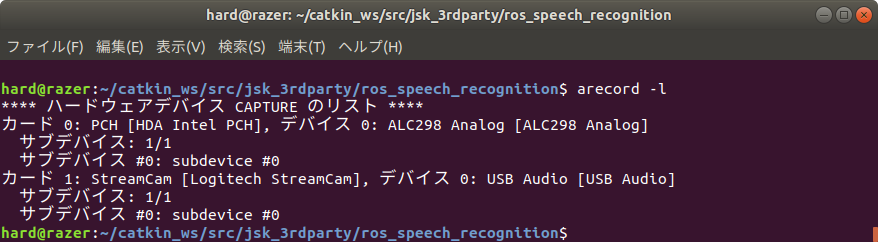
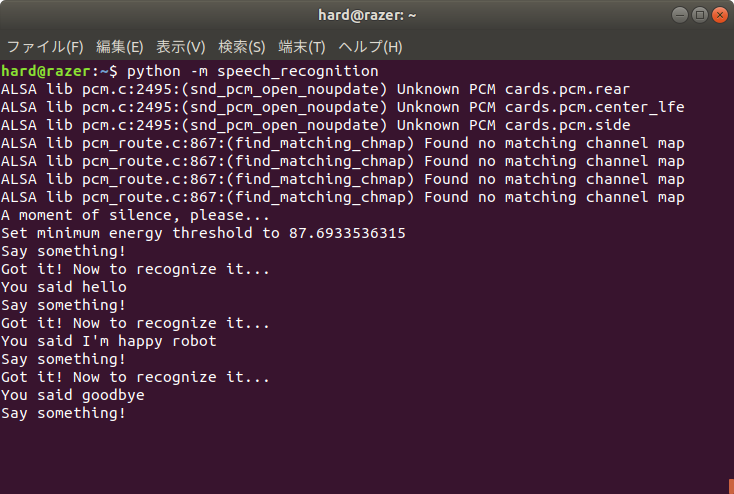
- 端末を開いて、次のコマンドでSpeechRecognitionを実行する。
- $ python -m speech_recognition
- デフォルトは英語の認識なのでマイクに向かって英語で何か話す。認識されると次のように”You said”の後に認識結果が表示される。
Pythonのサンプルプログラム
-
- 次に、上で実行したPythonのプログラムを見ていきましょう。まず、ソースコードを入手します。
- $ cd ~/src
- $ git clone https://github.com/Uberi/speech_recognition.git
- $ mkdir -p ~/src/hard2021/workshop4
- プログラムを次のファイルです。
- ~/src/speech_recognition/speech_recognition/__main__.py
- ソースコードsample.pyを表示します。
- 次に、上で実行したPythonのプログラムを見ていきましょう。まず、ソースコードを入手します。
import speech_recognition as sr
r = sr.Recognizer()
m = sr.Microphone()
try:
print("A moment of silence, please...")
with m as source: r.adjust_for_ambient_noise(source)
print("Set minimum energy threshold to {}".format(r.energy_threshold))
while True:
print("Say something!")
with m as source: audio = r.listen(source)
print("Got it! Now to recognize it...")
try:
# recognize speech using Google Speech Recognition
value = r.recognize_google(audio)
# we need some special handling here to correctly print unicode characters to standard output
if str is bytes: # this version of Python uses bytes for strings (Python 2)
print(u"You said {}".format(value).encode("utf-8"))
else: # this version of Python uses unicode for strings (Python 3+)
print("You said {}".format(value))
except sr.UnknownValueError:
print("Oops! Didn't catch that")
except sr.RequestError as e:
print("Uh oh! Couldn't request results from Google Speech Recognition service; {0}".format(e))
except KeyboardInterrupt:
pass
ROSパッケージ化
-
- では、このプログラムをROSパッケージ化しましょう。トピック通信の場合は大雑把にいうと次の4つを加えるだけです。
- ヘッダー
- ノード
- パブリッシャ
- サブスクライバとそのコールバック関数
- その他
- ROS化したソースコードspeech_recog.pyはこれになります!
- では、このプログラムをROSパッケージ化しましょう。トピック通信の場合は大雑把にいうと次の4つを加えるだけです。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import rospy # 1.ROS化:ヘッダ
import speech_recognition as sr
from std_msgs.msg import String
r = sr.Recognizer()
m = sr.Microphone()
rospy.init_node("speech_recog", anonymous=True) # 2. ROS化:ノード
# 3. ROS化:パブリッシャ
result_pub = rospy.Publisher("/speech_recog_result", String, queue_size=1)
try:
print("A moment of silence, please...")
with m as source: r.adjust_for_ambient_noise(source)
print("Set minimum energy threshold to {}".format(r.energy_threshold))
rate = rospy.Rate(10) # 5. ROS化:その他
while not rospy.is_shutdown(): # 5. ROS化:その他
print("Say something!")
with m as source: audio = r.listen(source)
print("Got it! Now to recognize it...")
try:
# recognize speech using Google Speech Recognition
value = r.recognize_google(audio, lang='en-US') # 日本語 jp-JP
# we need some special handling here to correctly print unicode characters to standard output
if str is bytes: # this version of Python uses bytes for strings (Python 2)
print(u"You said {}".format(value).encode("utf-8"))
result_pub.publish(value) # 3. ROS化:パブリッシャ関連
else: # this version of Python uses unicode for strings (Python 3+)
print("You said {}".format(value))
except sr.UnknownValueError:
print("Oops! Didn't catch that")
except sr.RequestError as e:
print("Uh oh! Couldn't request results from Google Speech Recognition service; {0}".format(e))
rate.sleep() # 5. ROS化:その他
except KeyboardInterrupt:
pass
ハンズオン
- sample.pyを実行してみよう!試しに次のスティーブン・ジョブズのスタンフォード大学卒業生に向けた有名なスピーチの最後の部分を発話して認識させてみましょう。
“Stay Hungry. Stay Foolish.” It was their farewell message as they signed off. Stay Hungry. Stay Foolish. And I have always wished that for myself. And now, as you graduate to begin anew, I wish that for you.
- 第2回、第3回のハンズオンを参考にspeech_recog.pyを使ったspeech_recogパッケージを作り、実行して動作を確認しよう!
- speech_recog.pyでは、Google Speech Recognitionサービスを使っていて、日本語にも対応してます。ソースコードを変更して試してみよう!なお、このサービスは登録なしで使えますがテスト用です。Googleの都合でいつ使えなくなるかわかりませんし、認識結果が帰って来ないときもあります。
- RoboCupなどの競技会では大会主催者はWiFi環境を準備していますが、通信の品質が悪い場合があります。そのため、オフラインでも音声認識できることが望まれます。SpeechRecognitionライブラリは、音声認識エンジンとしてオフライン用のCMU Sphinxも使えます。ただし、pocket sphinxのインストールが必要です。動作を確認しよう!
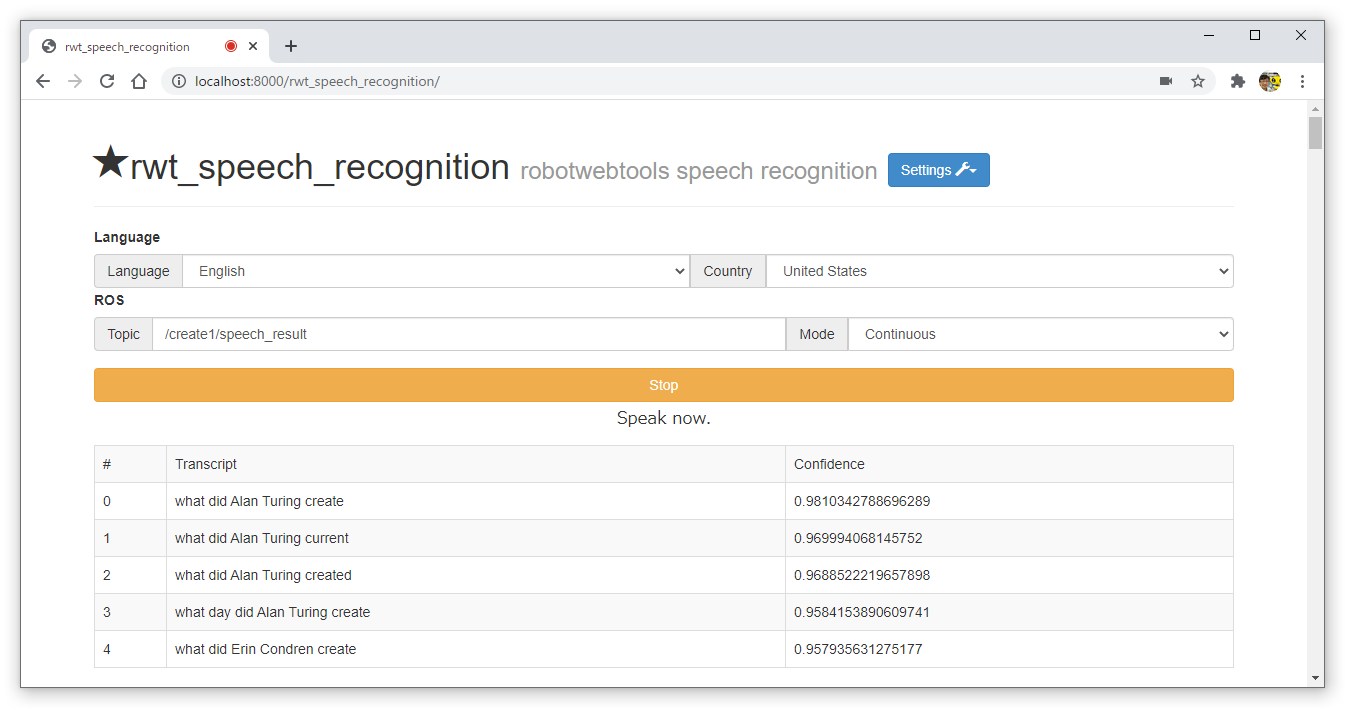
- speech_recog.pyでは、トピックのメッセージ型をstd_msgs/Stringとしましたが、recognize_google(audio, show_all=True, lang=’en-US’) とすると認識結果の複数候補とその信頼度が返却されます。そのデータをトピックとして送るために次のカスタム型を作成して、利用するプログラムを作ろう!
- speech_recognition_msgs/SpeechRecognitionCandidates.msg
- string[] transcript # candidate words of speech-to-text API
- float32[] confidence # confidence of transcript
- speech_recognition_msgs/SpeechRecognitionCandidates.msg
- なお、SpeechRecognitionはすでにYukiFurutaさんによってros_speech_recognitionパッケージになっており、上のハンズオンの答えが載っています。次の東大JSKのリポジトリからクローンできます。さらに、jsk_3rdpartyにはjulius_rosパッケージなど日本語の音声認識エンジンjuliusのROSパッケージもあります。優れたソースコードを読むことはとても勉強になり、そのうちバリバリ書けるようになることでしょう!
終わり
コメント