OpenCVが開発しているCVAT(Computer Vision Annotation Tool)への追加コンポーネントのインストールメモ。コンポーネントを追加することで自動アノテーションが可能となる。以下のリンクにしたがって作業した。ただし、現時点(2020-3-10)では、OpenVINOを最新バージョンにすると自動アノテーションでエラーが出たのでOpenVINOのバージョンは2019R3.1にしている。
参考リンク
- Quick Installation Guide: Advanced topics, CVAT
- Additional components
自動アノテーションに関する追加コンポーネント
- 自動アノテーションに関する追加コンポーネントは全部で5つあり、参考リンクにしたがって概要とインストール方法を説明している。使い方に関しては長くなるので別記事で作成予定。
- OpenVINOフォーマットの深層学習による自動アノテーション
- 参考リンク
- 概要
- OpenVINOフォーマットの深層学習を使って自動アノテーションが可能になる。OpenVINOフォーマットに対応している学習済みモデルはOpen Model Zooリポジトリに多くあるし、さらに、自分で作成したモデルをOpenVINOフォーマットに変換するとそれを使って自動アノテーションできる驚くべき機能。
- インストール
- 最新のOpenVINOツールキットの圧縮ファイル(.tgz)を以下のディレクトリに保存するだけ。ビルドする必要はない。とても簡単。いずれ改善されると思うが現時点では自動アノテーションで不具合がでるのでl_openvino_toolkit_p_2019.3.376.tgzを保存する。
- ~/src/cvat/components/openvino
- 以下のソフトウェア利用許諾契約を承認する。
- ~/src/cvat/components/openvino/eula.cfg
- ビルド:CVATをDockerでインストールしたのでDockerイメージをビルドする。
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/openvino/docker-compose.openvino.yml build
- 最新のOpenVINOツールキットの圧縮ファイル(.tgz)を以下のディレクトリに保存するだけ。ビルドする必要はない。とても簡単。いずれ改善されると思うが現時点では自動アノテーションで不具合がでるのでl_openvino_toolkit_p_2019.3.376.tgzを保存する。
- 実行
- Dockerでインストールしたので、Dockerコンテナの実行するとCVATを使える。
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/openvino/docker-compose.openvino.yml up -d
- Dockerでインストールしたので、Dockerコンテナの実行するとCVATを使える。
- OpenVINO学習済みモデルのダウンロード
- 必要に応じて以下の記事を参照にダウンロードする。
- 使い方
- 別記事で作成予定。
- Tensorflow物体検出
- 参考リンク
- 概要
- Tensorflowの以下のモデルを使った自動アノテーション機能。CPUまたはGPUで処理可能。詳細は参考リンクを参照。
- ビルド
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/tf_annotation/docker-compose.tf_annotation.yml build
- 実行
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/tf_annotation/docker-compose.tf_annotation.yml up -d
- 使い方
- 別記事で作成予定。
- NVIDIA GPUのサポート
- 参考リンク
- NVIDIA Dockerのインストール
- 以下のリンクに従いインストールする。
- インストールに成功すると以下のコマンドでnvidiaと表示される。
- $ docker info | grep ‘Runtimes’
- ビルド
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/cuda/docker-compose.cuda.yml build
- 実行
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/cuda/docker-compose.cuda.yml up -d
- Deep Extreme Cutによる半自動アノテーション
- 参考リンク
- 概要
- Deep Extreme Cutを使ったセマンテックとインスタンスセグメンテーションの半自動アノテーション機能。アノテーションをかけたい領域の4点(またはもっと)を指定するとあとは自動でしてくれる。Deep Extreme Cutについては以下のリンクと論文を参照
- ビルド
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/openvino/docker-compose.openvino.yml -f cvat/apps/dextr_segmentation/docker-compose.dextr.yml build
- 実行
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/openvino/docker-compose.openvino.yml -f cvat/apps/dextr_segmentation/docker-compose.dextr.yml up -d
- 使い方
- 別記事で作成予定。
- 自動セグメンテーション:Keras+Tensorflow Mask R-CNN
- 参考リンク
- 概要
- COCOデータセットで学習済みのMask R-CNN (バックボーン FPNとResNet101)を使った自動アノテーション。サポートするクラスは参考リンクを参照。
- ビルド
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/auto_segmentation/docker-compose.auto_segmentation.yml build
- 実行
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/auto_segmentation/docker-compose.auto_segmentation.yml up -d
- 使い方
- 別記事で作成予定。
追加コンポーネントを全て使いたい場合
- 上の説明では各コンポーネントごとのDockerイメージの作成とコンテナの実行方法を説明している。追加コンポーネントを全て使いたい場合は以下のコマンドを実行する。
- Dockerイメージのビルド
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/openvino/docker-compose.openvino.yml -f components/tf_annotation/docker-compose.tf_annotation.yml -f components/cuda/docker-compose.cuda.yml -f cvat/apps/dextr_segmentation/docker-compose.dextr.yml -f components/auto_segmentation/docker-compose.auto_segmentation.yml build
- Dockerコンテナの実行
- $ cd ~/src/cvat
- $ docker-compose -f docker-compose.yml -f components/openvino/docker-compose.openvino.yml -f components/tf_annotation/docker-compose.tf_annotation.yml -f components/cuda/docker-compose.cuda.yml -f cvat/apps/dextr_segmentation/docker-compose.dextr.yml -f components/auto_segmentation/docker-compose.auto_segmentation.yml up -d
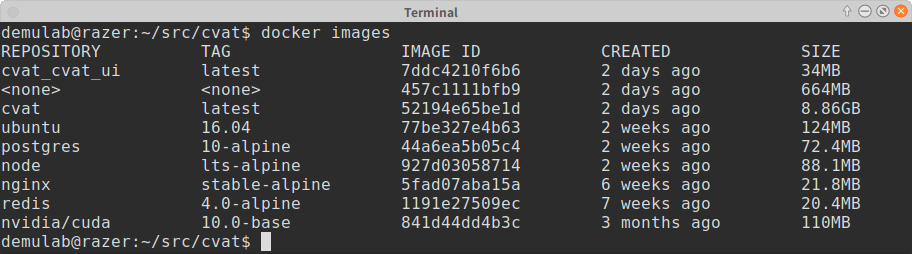
- 私の環境では全部入りするとcvatのイメージが8.86GBになった。docker imagesコマンドで確認できる。
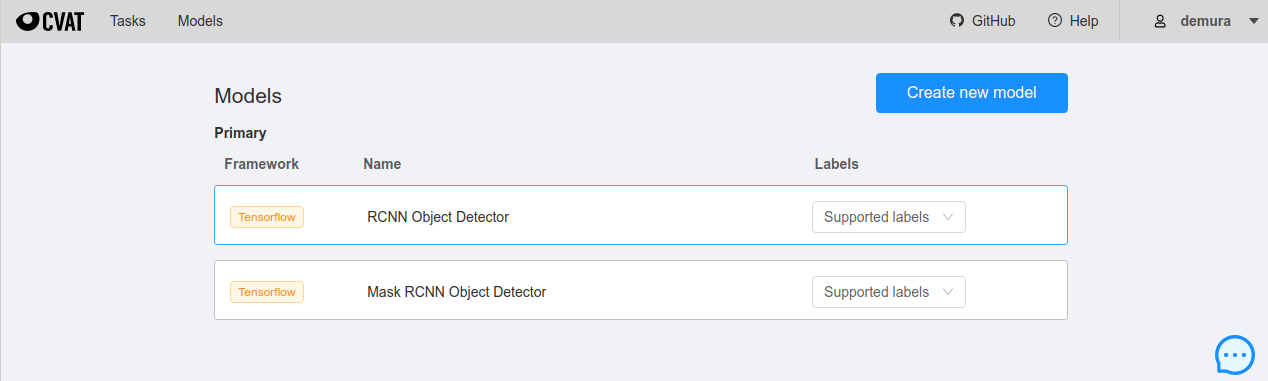
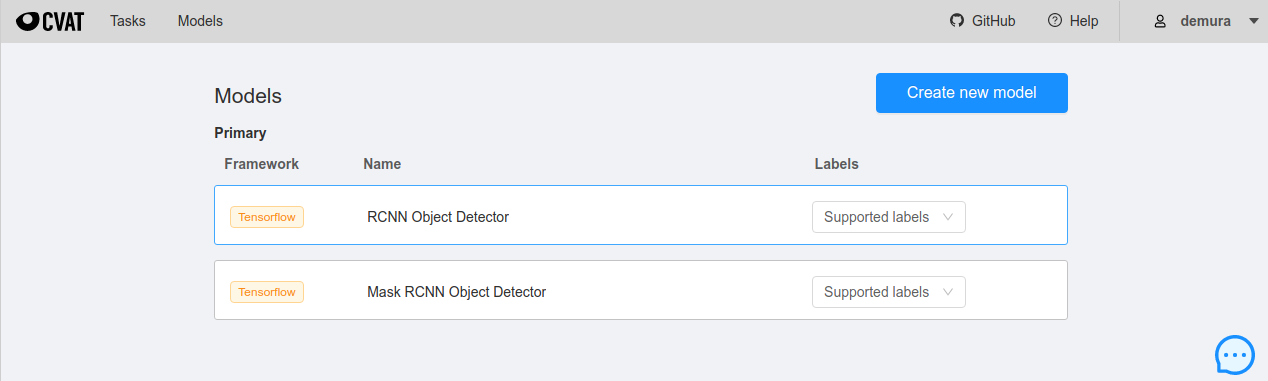
- CATのスクリーンショット。追加コンポーネントを入れるとModelsにRCNN Object DetectorとMask RCNN Object Detectorが追加される。Deep Extreme Cutのモデルはここには表示されない。
 終わり
終わり
コメント