この記事はHARD2020(Home AI Robot Development)ワークショップ用です。 今回はSpeech APIを使ったROSの音声認識パッケージrwt_speech_recognitionをWSL2で使用する方法を紹介します。ネイティブUbuntuの方は別のページをご覧ください。開発者furushchevさんの詳しい日本語の解説記事もありますので参考リンクもご覧ください。なお、WSL2でrwt_speech_recognitionを使うための手法を追加している部分はオリジナルとなります。
参考リンク
- ROSを使ってWebインターフェース経由で音声認識する by @furushchevさん
- https://github.com/tork-a/visualization_rwt by Tokyo Opensource Robotics Kyokai Association
- Web Speech API
作業環境
- Windows10 WSL2のUbuntu18.04
- ROS Melodic
- Google Chrome 85.0.4183.83(Official Build)64 ビット)(他のブラウザは対応してないようです)
- Webカメラ:ロジクールStream CAMとASUS ROG EYEで確認済み(私のPC内臓マイクでは動作しませんでした)
準備
- 以下のサイトの説明に従い、アプリ「リモートデスクトップ(WebSocket)」のプライベートとパブリックにチェックを入れて、ファイアウォール経由の通信を許可する。なお、Windows10 Homeの場合はリモートデスクトップ(WebSocket)がないので、音声認識のときだけ一時的にファイアウォールを無効にしてください。
- Windowsのアプリと通信するために環境変数を設定する。~/.bashrcに以下を追加する。ROS_MASTER_URIはROSノードを複数のネットワークで使用する場合に必要になる。
export ROS_MASTER_URI=http://$(ifconfig | grep 'inet 172.26' | awk '{print $2}'):11311/

インストール
- 以下のサイトのとおり実施した。推奨されているaptでのインストールはmelodic用のパッケージが見つけられなかったのでソースからビルドした。wstoolはワークスペースのバージョン管理システム。https://github.com/tork-a/visualization_rwt
- ワークスペースを初期化する。
$ cd ~/catkin$ wstool init src
- ワークスペースに新しいリポジトリを設定する。
$ cd src$ wstool set visualization_rwt --git https://github.com/tork-a/visualization_rwt/
- ワークスペースのリポジトリをアップデートする。
$ wstool update
- 依存関係の解消
$ cd ~/catkin_ws$ rosdep install --from-paths src --ignore-src --rosdistro ${ROS_DISTRO} -r -y
- ビルド
$ catkin build visualization_rwt
実行
- rwt_speech_recognitionノードの実行(Ubuntuでの実行)
- Ubuntu端末を開き、以下のコマンドを実行する
$ roslaunch rwt_speech_recognition rwt_speech_recognition.launch
- Ubuntu端末を開き、以下のコマンドを実行する
- Chromeブラウザの起動(Windowsでの実行)
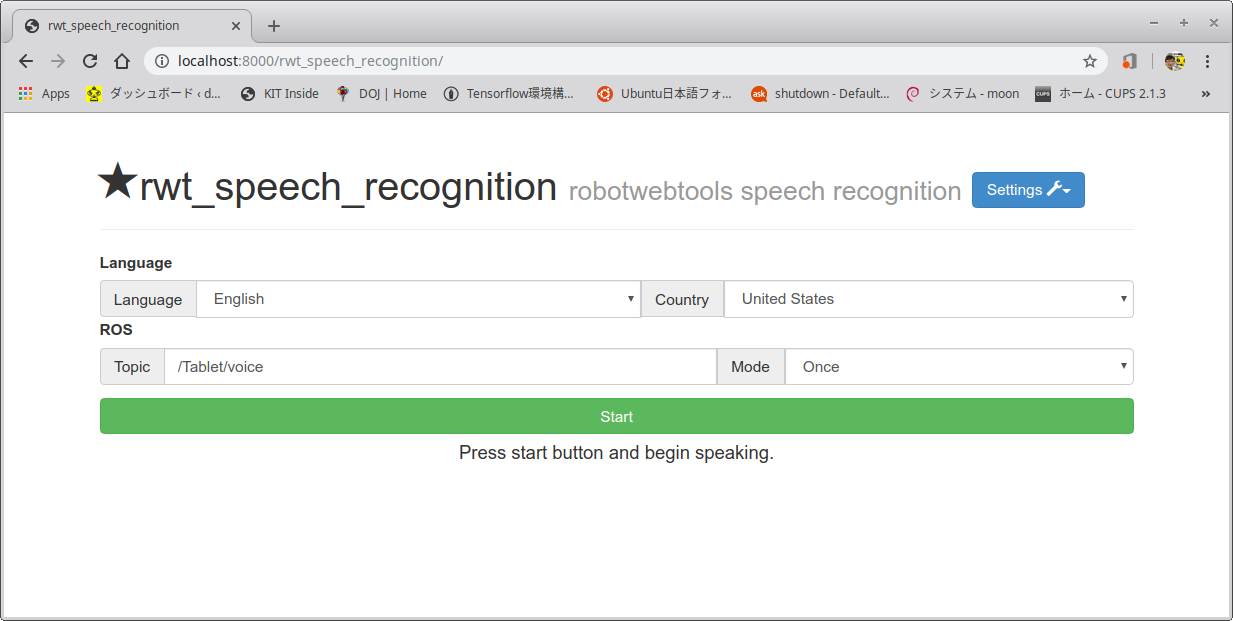
- 以下のリンクをクリックするかChromeブラウザを起動し以下のアドレスを検索窓に入れる。これを実施する間に実行1のrwt_speech_recognitionノードを実行しておかねばならない。
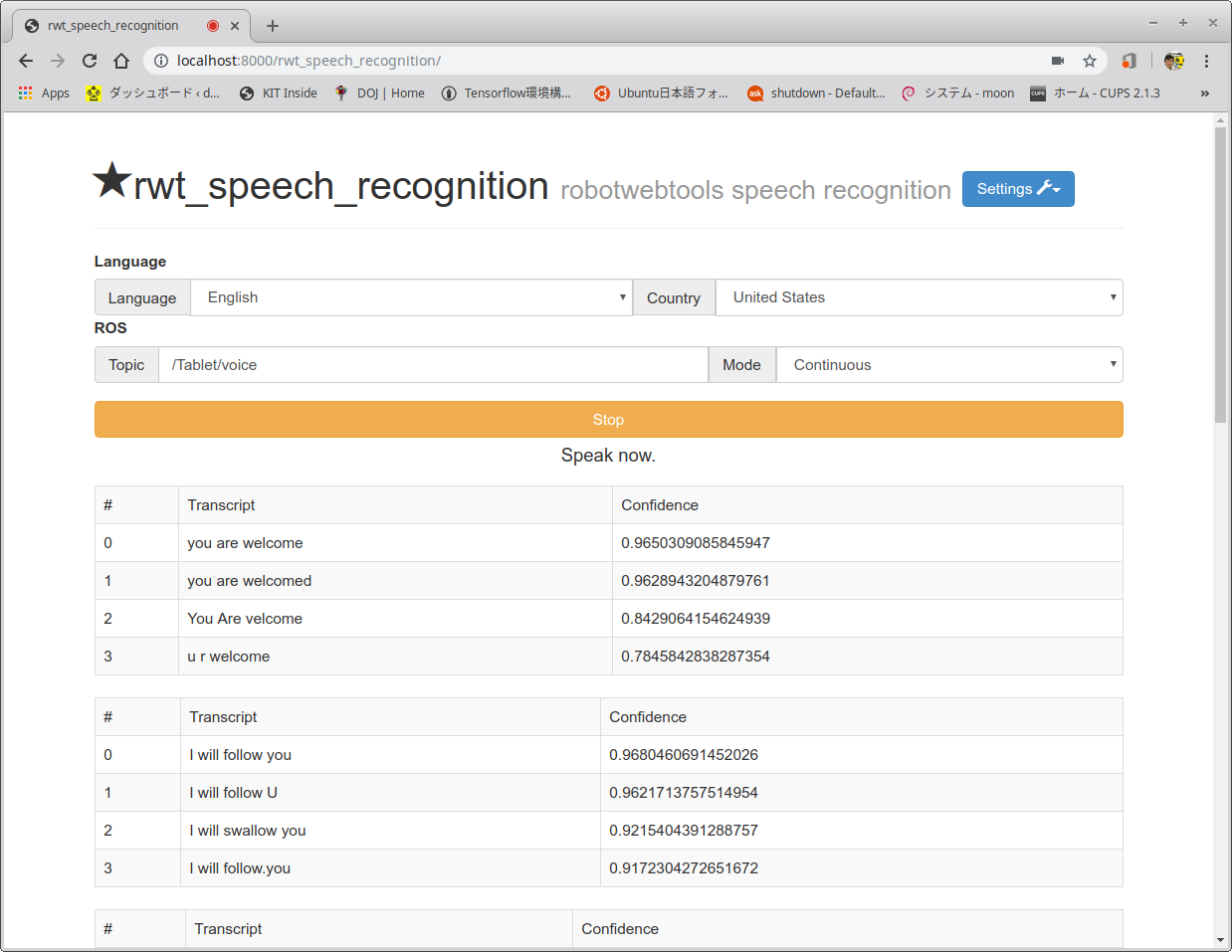
- 音声認識をスタートさせるためには、以下のChrome画面で緑に塗られているStartボタンをクリックする。
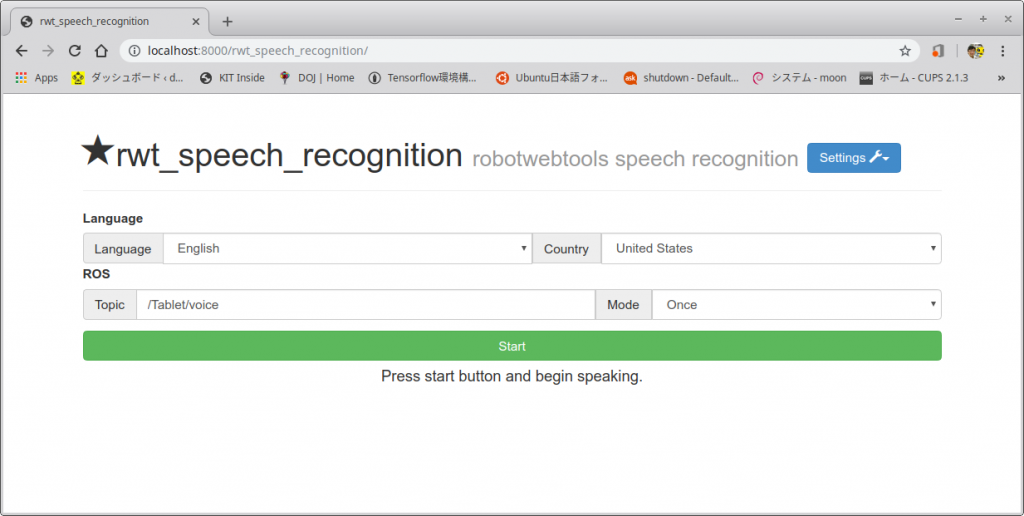
- Chromeの画面のマイクに英語で話しかけ、認識結果が表示されていれば成功。日本語で話しかけたい場合はブラウザのLanguageを日本語にすればよい。デフォルトではROSのトピック名が/Tablet/voiceになっているが、この画面から自由に変更できる。なお、連続して音声認識をしたい場合はModeをContinuousにすればよい。
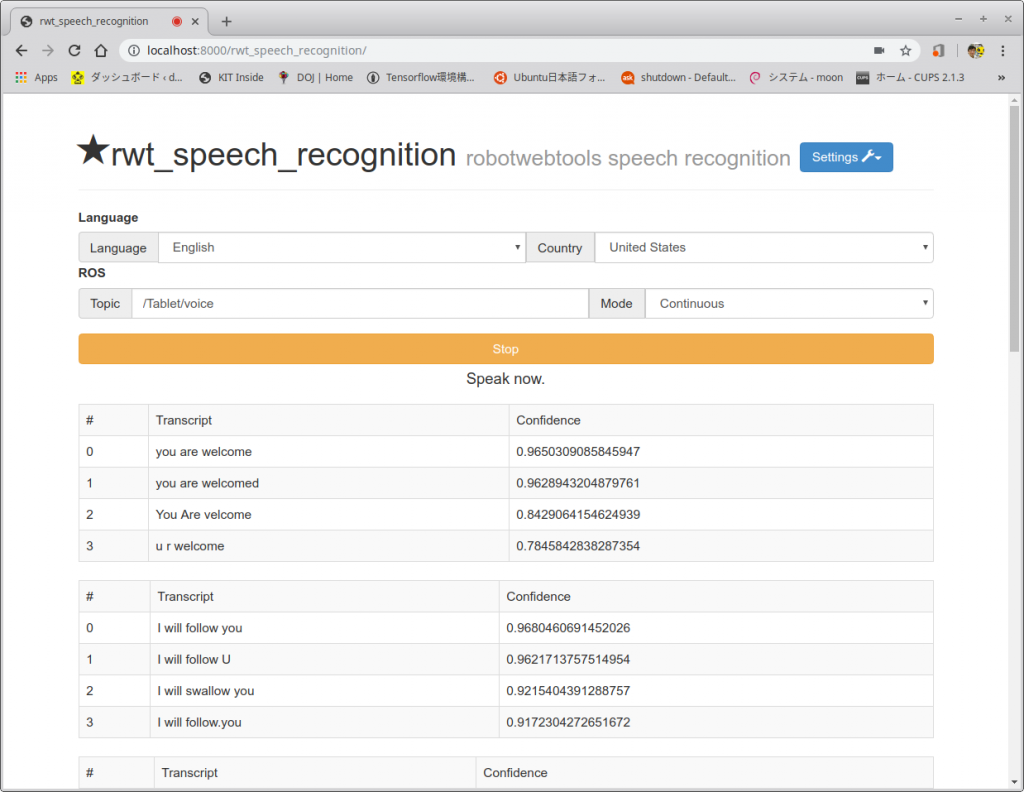
- トピックの確認(Ubuntuでの実行)
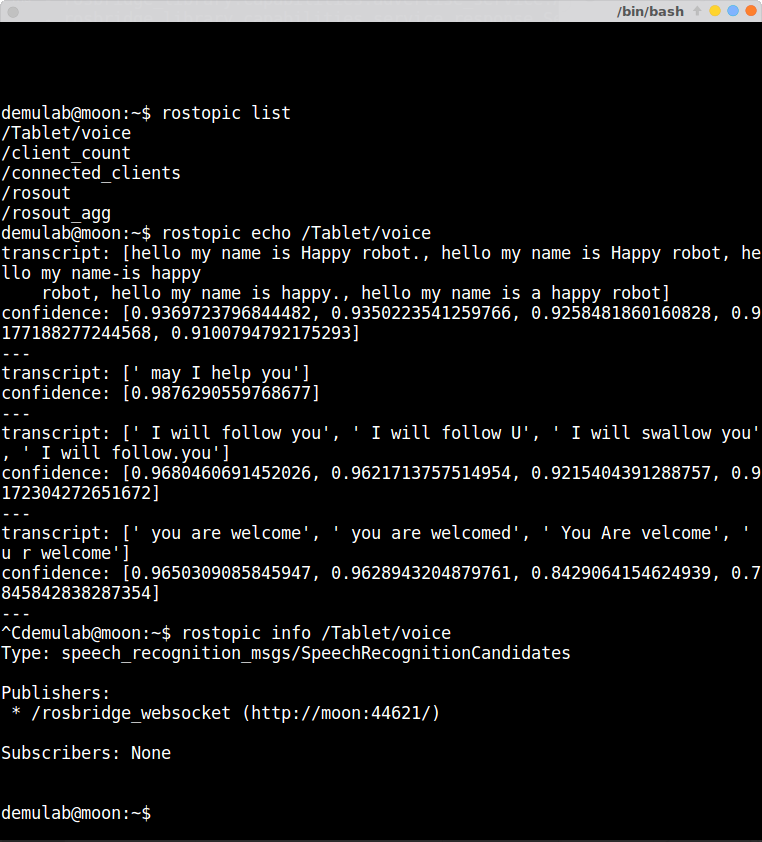
- では、最後にトピックを確認しよう。別の端末を開き、以下のコマンドで認識結果のトピック/Tablet/voiceを表示する。
$ rostopic echo /Tablet/voice
- では、最後にトピックを確認しよう。別の端末を開き、以下のコマンドで認識結果のトピック/Tablet/voiceを表示する。
-
- うまくいかない場合は、インストールの作業を繰り返してみよう。私の環境ではそれで問題が解決した。
- カスタマイズ
- デフォルトではトピック名が”/Tablet/voice”になっているが、このワークショップの他のトピック名と合わせるために”/create1/speech_result”に変更する。具体的な作業としては、以下のファイル29行目のvalueの値を”/create1/speech_result”に変更する。
- ~/catkin_ws/src/visualization_rwt/rwt_speech_recognition/www/index.html
- デフォルトではトピック名が”/Tablet/voice”になっているが、このワークショップの他のトピック名と合わせるために”/create1/speech_result”に変更する。具体的な作業としては、以下のファイル29行目のvalueの値を”/create1/speech_result”に変更する。
エラー処理
- 次のようなdbus errorと出た場合は、dbusが起動していないので次のコマンドを実行してdbusをスタートさせる。
- Failed to connect to system bus: Failed to connect to socket /var/run/dbus/system_bus_socket
$ sudo /etc/init.d/dbus start
- Failed to connect to system bus: Failed to connect to socket /var/run/dbus/system_bus_socket
- それでも動かないとき
- 一時的にWindows Defender ファイヤウォールを無効にする。
お疲れさま!
終わり
コメント