
Detectron2でカスタムデータセット学習メモの続き。長くなったので学習と推論に分けた。以下のDetectron2 Beginner’s Tutorialをもとに説明を加えたもの。TutorialがGoogle ColabのJupyterノートブックを使っているのでローカルマシンで動くようにPythonスクリプトを少し変更している。
学 習
- カスタムデータで学習してない場合は以下のリンクでまず学習をする。
推 論
- 以下のスクリプトを~/src/detectron2/myprog/balloon_inference.pyとして保存する。
# balloon_inference.py
import cv2
import json
import numpy as np
import os
import random
from detectron2 import model_zoo
from detectron2.utils.visualizer import ColorMode
from detectron2.config import get_cfg
from detectron2.engine import DefaultPredictor
from detectron2.engine import DefaultTrainer
from detectron2.structures import BoxMode
from detectron2.utils.visualizer import Visualizer
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
"iscrowd": 0
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
if __name__ == '__main__':
train_dataset_name = "balloon_train"
val_dataset_name = "balloon_val"
val_dicts_name = "balloon/val"
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get(train_dataset_name)
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
# Pretraied weights
# cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
# Weights trained by a custom dataset
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth") #
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set the testing threshold for this model
cfg.DATASETS.TRAIN= (train_dataset_name, )
cfg.DATASETS.TEST = (val_dataset_name, )
cfg.DATALOADER.NUM_WORKERS = 2
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 300 # 300
# faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon)
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg) # trainer is used in evaluation
trainer.resume_or_load(resume=False)
# train is not need for the inference and evaluation phase
# trainer.train()
# Inference
predictor = DefaultPredictor(cfg)
dataset_dicts = get_balloon_dicts(val_dicts_name)
for d in random.sample(dataset_dicts, 3):
im = cv2.imread(d["file_name"])
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1],
metadata=balloon_metadata,
scale=0.8,
# remove the colors of unsegmented pixels
instance_mode=ColorMode.IMAGE_BW )
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2.imshow("Inference", v.get_image()[:, :, ::-1])
#cv2.waitKey(0)
cv2.waitKey(2000) # wait for 2000ms
cv2.destroyAllWindows()
# Evaluation
evaluator = COCOEvaluator(val_dataset_name, cfg, False, output_dir="./output/")
val_loader = build_detection_test_loader(cfg, val_dataset_name)
inference_on_dataset(trainer.model, val_loader, evaluator)
推 論
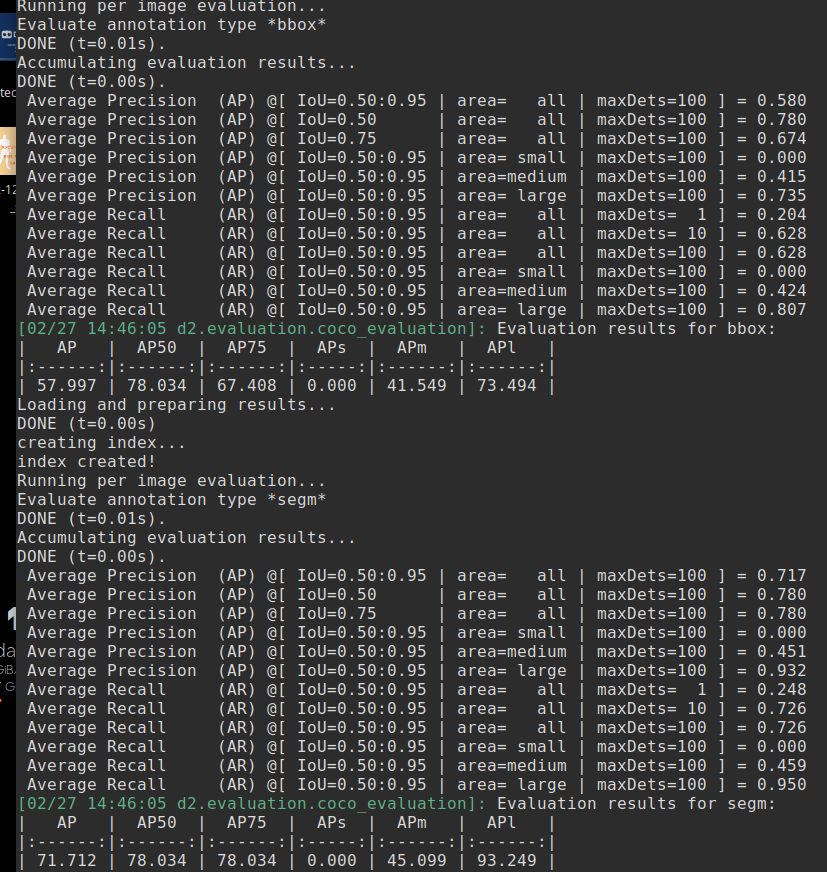
- 次のコマンドを実行すると、写真のような風船が推論されたウインドウが開く。各ウインドウは2秒毎に切り替わり、全部で3枚表示される。その後、評価が始まる。
$ cd ~/src/detectron2/datasets$ python3 ../myprog/balloon_inference.py
エラーの対応
- 2020年2月27日時点では、coco APIの問題でnumpyのバージョンが1.18以上だとEvaluationすると次のエラーが出る。それを回避するためにnumpyのバージョンをダウンする。
- object of type <class ‘numpy.float64’> cannot be safely interpreted as an integer
- numpy
- バージョンの確認
$ pip3 show numpy
Name: numpy
Version: 1.18.1
Summary: NumPy is the fundamental package for array computing with Python.
Home-page: https://www.numpy.org
Author: Travis E. Oliphant et al.
Author-email: None
License: BSD
Location: /home/demulab/.local/lib/python3.6/site-packages
Requires:
- numpyのバージョンダウン
$ pip3 uninstall numpy$ pip3 install numpy==1.17.0





コメント