この記事はHARD2021(Home AI Robot Development)ワークショップ用です。 本記事ではROSを使った簡単な質問応答システムを作ってみましょう。言語は英語だけです。日本語には対応していません。なお、RoboCup@Home Educationの世界大会やWorld Robot Summitの使用言語は英語だけです。英語で動作するシステムを開発しないと大会には参加できません。さらに、英語の勉強にもなるので一石二鳥ですね。Japan Openでは日本語も使えますが英語でもOKです。
ソースコードの説明
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys, copy, rospy, time
import subprocess, ngram
import numpy as np
from std_msgs.msg import String
from speech_recognition_msgs.msg import SpeechRecognitionCandidates
class QuestionAnswer:
# コンストラクタ
def __init__(self):
rospy.init_node('question_answer',anonymous=True) # ノードの初期化
self.recog_transcript = [] # 認識結果
self.question_all_no = 10 # 全問題数
self.question_no = 3 # 質問の回数
self.answer_count = 0 # 回答数
# 質問文
self.sentence_all = [
"Who are the inventors of the C programming language?", #1
"Who is the inventor of the Python programming language?", #2
"Where does the term computer bug come from?", #3
"What is the name of the round robot in the new Star Wars movie?", #4
"What did Alan Turing create?", #5
"What Apollo was the last to land on the moon?", #6
"Who developed the first industrial robot?", #7
"Which company makes ASIMO?", #8
"How many people live in the Germany?", #9
"What city is the capital of the Germany?" #10
]
# 解答文
self.sentence_answer = [
"Ken Thompson and Dennis Ritchie", #1
"Guido van Rossum", #2
"From a moth trapped in a relay", #3
"BB-8", #4
"Many things like Turing machines and the Turing test", #5
"Apollo 17", #6
"The American physicist Joseph Engelberg. He is also considered the father of robotics.", #7
"Honda", #8
"A little over 80 million", #9
"Berlin" #10
]
# subscriber
rospy.Subscriber('/create1/speech_result',SpeechRecognitionCandidates, self.speech_recog_cb)
# publisher
self.speak_pub = rospy.Publisher('/tts', String, queue_size=10)
# ウエルカムメッセージ
time.sleep(1) # この間を入れないと次の文を発話しない
self.speak("Welcome to the Hard Question answering system. Please ask me a question after a beep sound", 8)
# 音声認識コールバック関数。認識した結果が引数recogに入る。
def speech_recog_cb(self,recog):
self.recog_transcript = recog.transcript # 認識結果の文
self.confidence = recog.confidence # 認識結果の信頼度
# 発話
def speak(self, sentence, sleep_time=3.5):
self.speak_pub.publish(sentence)
time.sleep(sleep_time) # pubulishした後に少しスリープが必要。秒数は調整すること
# 質問のタイミングを示すビープ音
def beep(self):
time.sleep(0.3)
args = ['/usr/bin/paplay', '/usr/share/sounds/freedesktop/stereo/complete.oga']
subprocess.call(args)
# メイン関数
def main(self):
rate = rospy.Rate(1)
time.sleep(1) # 少し間を置く [s]
speech_recog.beep() # 回答を促すビープ音
while not rospy.is_shutdown():
max_k = 0
max_no = 0
max_val = 0
time.sleep(1)
rospy.loginfo(self.recog_transcript)
# 文章間の類似度を計算する。音声認識結果は完全ではないのでに近い質問があるか調べる。
# 文章間の類似度を計算する方法はいろいろあるが、ここではN-gramを使う手法を用いている。
# recog_transcriptには複数の音声認識結果の文章が格納されているので、それら全てと
# 全質問文の類似度を計算して、一番類似度の高い文章を質問文としている。
if len(self.recog_transcript) > 0: # 音声認識結果がある場合だけ処理。
for i in range(0, self.question_all_no):
for k in range(0, len(self.recog_transcript)):
rospy.loginfo(self.recog_transcript[k])
val = ngram.NGram.compare(self.recog_transcript[k], self.sentence_all[i])
if val >= max_val:
max_k = k
max_no = i
max_val = val
rospy.loginfo('max_val=%s', str(max_val))
if max_val >= 0.3: # 類似度の最大値が0.3以上なら。この値は調整必要。
self.speak('Answer', 1)
self.speak(self.sentence_answer[max_no], 5)
rospy.loginfo("answer[%d]:%s",max_no, self.sentence_answer[max_no])
print(self.confidence)
del self.recog_transcript[:]
time.sleep(3)
self.answer_count = self.answer_count + 1
if self.answer_count < self.question_no:
speech_recog.beep() # 回答を促すビープ音
time.sleep(1) # 少し間を置く [s]
else:
self.speak('Congratulations! You are a quiz king!', 3)
sys.exit() # プログラム終了
rate.sleep()
if __name__ == '__main__':
try:
question_answer = QuestionAnswer()
question_answer.main()
except rospy.ROSInterruptException: pass
準備
- 端末で次のコマンドを実行する。
$ pip install ngram
パッケージの作成
- 次のコマンドでspeech_recogパッケージを作りましょう!
$ cd ~/catkin_ws/src/hard2021$ catkin_create_pkg question_answer roscpp rospy std_msgs
ソースコードの作成
- エディタを開き、上のソースコードをコピペしてセーブする。以下のコマンドはエディタにgeditを使う場合。
$ cd ~/catkin_ws/src/hard2021/question_answer/src$ gedit question_answer.py
ビルド
- Pythonはビルドする必要はないが、ROSでカスタムメッセージ型を使用する場合は必要になる。さらに、catkin buildをしないと、ROSにパッケージとして認識しないのでroscdやrosrunコマンドが使えない。
$ cd ~/catkin_ws$ catkin build question_answer
- 作成したpythonプログラムに実行権を与える。実行権を与えないとrosrunコマンドで実行できない。
$ source ~/.bashrc$ roscd question_answer/src$ chmod u+x question_answer.py
実行
- 以下の説明の順番どおりに実施してください。
- 音声認識ノードの起動
- Ubuntu端末を開き、以下のコマンドを実行してrwt_speech_recognitionノードを起動する
$ roslaunch rwt_speech_recognition rwt_speech_recognition.launch
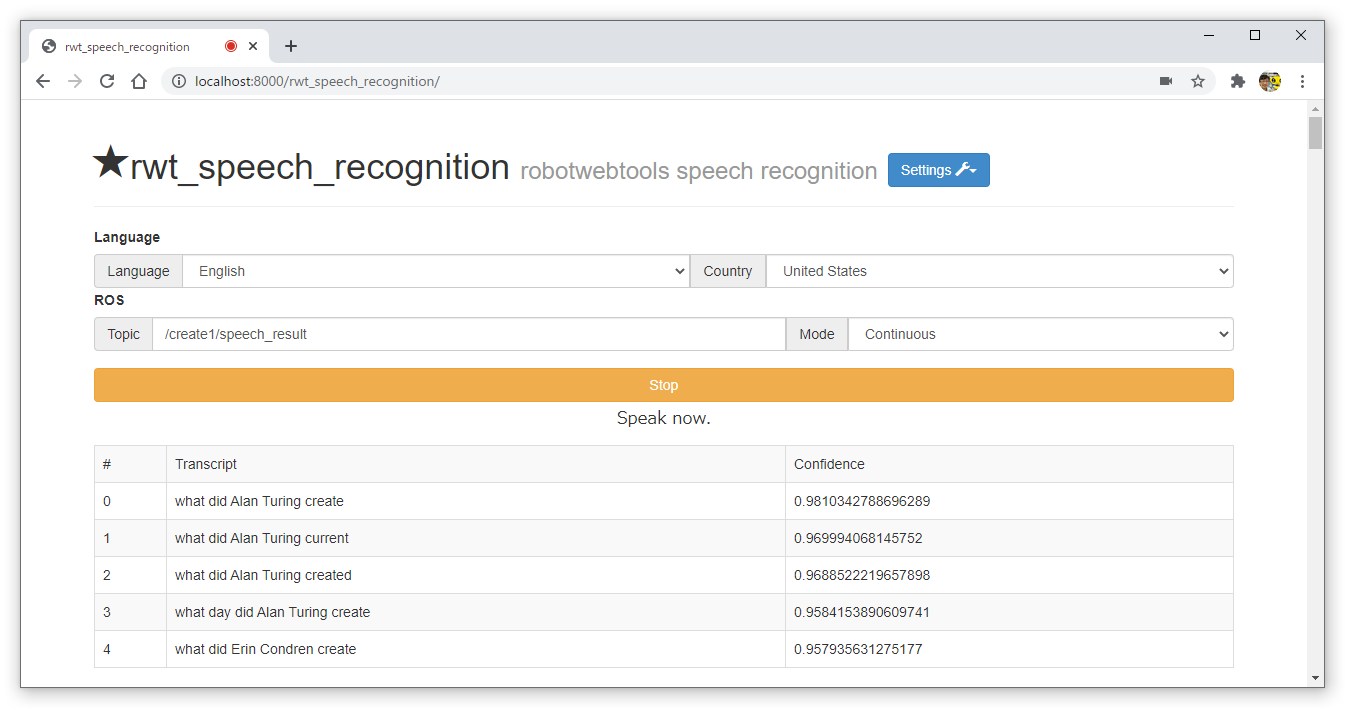
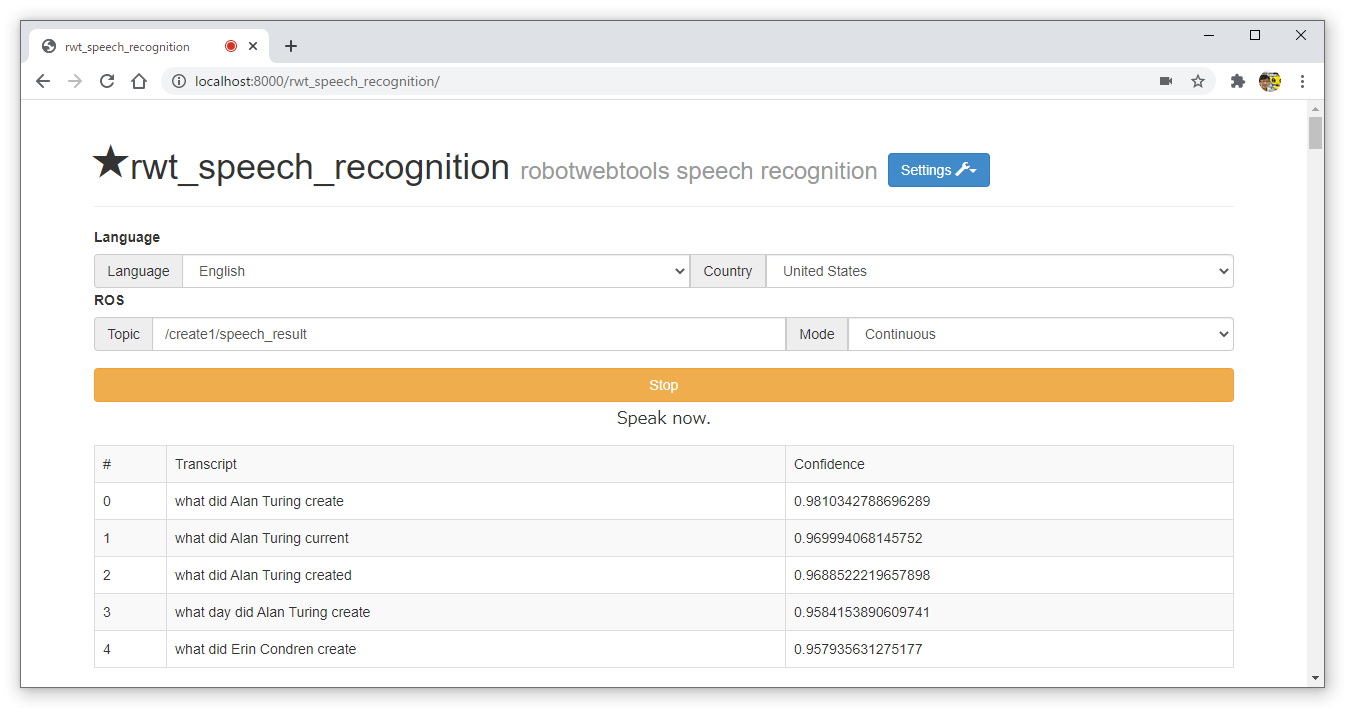
- WindowsのChromeブラウザの起動して、以下のURLにアクセスする。
- http://localhost:8000/rwt_speech_recognition/
- [English]を選択し、[Continuous]モードにして、[Start]を押して音声認識をスタートする。
- ROS Topicが”/create1/speech_result”になっているか確認する。なっていない場合はサンプルプログラムが動作しないので以下のファイルの29行目のvalueの値を”/Tablet/voice”から”/create1/speech_result”に変更する。
- ~/catkin_ws/src/visualization_rwt/rwt_speech_recognition/www/index.html
- 28行目変更前:

- 28行目変更後:

- Ubuntu端末を開き、以下のコマンドを実行してrwt_speech_recognitionノードを起動する
- 音声合成ノードの起動
- (WSL2だけの作業)Windowsのエクスプローラーで以下のファイルをダブルクリックしてPulseAudioサーバーを起動する。
- C:\WSL\pulseaudio-1.1\bin\pulseaudio.exe
- 端末を開き、次のコマンドを実行して音声合成ノードpicottsを起動する。
$ rosrun picotts picotts.exe
- オプション:クオリティが高いmicrosoftやgoogleの音声合成エンジンに変更してみよう。別の端末を開き以下を実行する。
- Microsoft
$ rostopic pub /picotts/engine std_msgs/String "microsoft"
- Google
$ rostopic pub /picotts/engine std_msgs/String "google"
- Microsoft
- (WSL2だけの作業)Windowsのエクスプローラーで以下のファイルをダブルクリックしてPulseAudioサーバーを起動する。
- 質問応答ノードの起動
- 端末を開き、次のコマンドを実行して質問応答ノードを起動する。
$ rosrun question_answer question_answer.py
- 端末を開き、次のコマンドを実行して質問応答ノードを起動する。
ハンズオン
- 質問応答システムを起動して、以下の英文を発音に注して質問してみよう。なお、この質問はRoboCup世界大会2016 RoboCup@HomeリーグのSpeech Recognition Testで使われたものの一部です。
- “Who are the inventors of the C programming language?”
- “Who is the inventor of the Python programming language?”
- “Where does the term computer bug come from?”
- “What is the name of the round robot in the new Star Wars movie?”
- “What did Alan Turing create?”
- “What Apollo was the last to land on the moon?”
- “Who developed the first industrial robot?”
- “Which company makes ASIMO?”
- “How many people live in the Germany?”
- “What city is the capital of the Germany?”
- 2つの文章間の類似度を計算する手法はいろいろあります。調べる前にPythonの標準モジュールだけを用いて類似度を計算する関数を実装してみよう。調べる前に自分で考えて実装することが今後の財産になります。
- このサンプルプログラムでは2つの文章間の類似度を計算するのにN-gramを用いています。この手法について調べて理解しよう。
- 2つの文章間の類似度を計算する手法はいろいろあります。調べて複数の方法を実装して違いを調べてみよう。さらに、自分が考えていた手法とも比較してみよう。
発 展
- 今後、2つの文章間の意味までも考慮して類似度を計算することが必要になると思います。自然言語処理という研究分野になります。勉強したい方は以下の書籍を紹介します。
終わり
コメント